|
главная о нас продукты скачать демо технологии ^
| Диссертация А.Сокирко "Семантические словари в автоматической обработке текста (по материалам системы ДИАЛИНГ)" |
Введение
Глава 1. Обзор литературы
Глава 2. Досемантический анализ русского текста
Глава 3. Первичный семантический анализ русского текста
Глава 4. Синтез английского текста
Заключение
Литература
Выступление на защите
| Выступление А.В.Сокирко на защите кандидатской диссертации |
^ |
Уважаемый
председатель, уважаемые члены Совета, тема моей диссертации "Семантические
словари в автоматической обработки текста (по материалам системы Диалинг)".
Я думаю, что ни у кого нет сомнений
в том, что системы анализа естественного текста до сих пор остаются одним из
актуальнейших направлений информатики.
Среди таких систем особо выделяются программы машинного перевода, поскольку для их адекватного
функционирования требуется очень глубокое понимание входного текста. Российские системы
машинного перевода всегда выполнялись на очень высоком уровне, а некоторые из
них стали прародителями целых научных школ, а именно такие системы, как
-
Системы ФР1 и ФР2;
- Системы
ЭТАП;
- Система
ФРАП;
- Система Ретранс.
Cистемы машинного перевода обычно
строятся модульно, где каждый модуль принимает на вход некоторое представление
текста и вырабатывает свое выходное представление.
Некоторые процессоры имеют уже устоявшиеся названия и функции, например,
морфологический процессор отвечает за лемматизацию входного текста. Система
машинного перевода с русского на английский Диалинг, речь о которой идет в представленной диссертации, имеет некоторые свои особые процессоры, часть
из которых была унаследована у системы ФРАП, а часть была сделана внутри этой
системы.
|
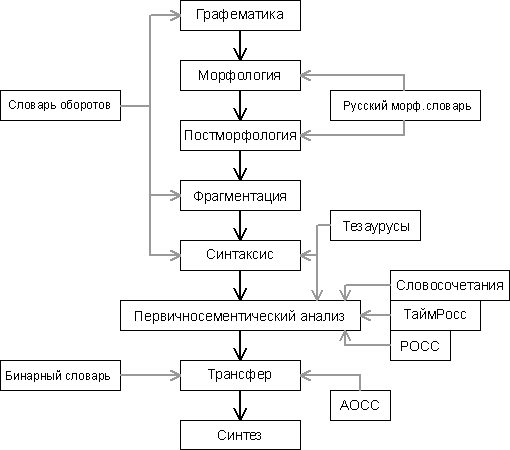
Схема
1. Общая схема русско-английского машинного переводчика ДИАЛИНГ |
^ |
Первый процессор – графематический
анализ. Этот модуль разбивает входной текст на слова, цифровые комплексы,
неизменяемые обороты, электронные
адреса, названия файлов, некоторые виды аббревиатур. Кроме того, эта программа
делит текст на предложения, абзацы, ищет заголовки, пункты перечисления. Автору
данной диссертации принадлежит реализация этого модуля в системе ДИАЛИНГ.
|
Таблица 2. Графематический анализ |
^ |
|
Графем. дескриптор |
Объяснение |
Пример |
|
ЛЕ |
русская лексема |
Иван |
|
ИЛЕ |
иностранная лексема |
John |
|
ЗПР |
знак препинания |
".", "[", "]", "(" |
|
ЦК |
цифровой комплекс |
1234 |
|
ЦБК |
цифро-буквенный комплекс |
34h |
|
ПРД1 –ПРД2 |
начало и
конец предложения |
|
|
ИМ? |
вероятное
имя |
|
|
ОБ1-ОБ2 |
устойчивый
оборот |
|
|
АБ1-АБ2 |
аббревиатура |
|
|
ДТ1-ДТ2 |
дата |
|
|
ЭА1-ЭА2 |
электронный
адрес |
|
|
Заг1,...,Загn |
заголовки |
|
|
УП1,..., УПn |
условно
предложения |
|
Второй процессор – традиционный
морфологический анализ, построен на
электронной версии грамматического словаря Зализняка. Этот модуль осуществляет морфосинтез и лемматизацию.
Русский морфологический словарь:
Грамматический словарь А.А. Зализняка,
Дополнительные перечни
- Лемматизация:
Словоформа -> {Лемма, Часть
Речи, Граммемы}
- Морфосинтез:
{Лемма, Часть Речи, Граммемы} ->
Словоформа
- Часть речи:
С(уществительное),
Г(лагол), П(рилагательное)…
- Граммемы:
ед(единственное
число), им(именительный падеж) …
Третий процессор системы Диалинг –
постморфологический анализ. Основная цель этого процессора – уничтожение
очевидной омонимии по ближайшему контексту и достройка морфологической
интерпретации.
Четвертый процессор системы Диалинг
– фрагментация и синтаксический анализ. Фрагментация – это процедура построения
фрагментов (простых предложений или клауз) в составе сложного. Синтаксический
анализ – процедура построения групп внутри фрагментов. Главное отличие
фрагмента от группы заключается в том, что фрагмент не должен быть полностью
проанализированным, в то время как в группе каждое слово должно удовлетворять
каким-то синтаксическим или морфологическим свойствам. Синтаксические группы
покрывают текст только на 80 процентов,
что означает, что часть морфологической омонимии остается неразрешенной.
Фрагмент F = {W, R, C, T}, где
W – слова, которые составляют фрагмент;
R – главное слово фрагмента;
С – союз
фрагмента;
T – тип фрагмента.
Типы фрагментов:
|
Типы фрагментов |
Пример |
|
ГЛ_ЛИЧН |
Я ушел |
|
ИНФИНИТИВ |
уйти домой |
|
ДПР |
Придя домой |
|
КР_ПРЧ |
Я съеден |
|
КР_ПРИЛ |
Она красива |
|
ПРЕДК |
Мне интересно |
|
ПРЧ |
Доведенный до отчаяния |
|
ВВОД |
По всей вероятности |
|
ТИРЕ |
Полина – герой |
|
СРАВН |
Саша краше, чем Маша |
|
НСО |
Свободный от вредных привычек человек |
|
ПУСТЫХА |
Дом |
Пример:
Я видел дом, который построил Петя
F1 = {" Я видел дом ",
" видел ", 0, ГЛ_ЛИЧН}
F2 = {" который построил
Петя ", " построил ", "который", ГЛ_ЛИЧН}
F1 => F2
(F1 иерархически подчиняет F2).
Группа G = {Т, START, END, START_MAIN, END_MAIN}, где
T – тип фрагмента;
Start – первое слово группы;
End – последнее слово группы;
Start_Main – первое слово главной подгруппы;
End_Main – последнее слово главной подгруппы.
Типы групп:
|
Название |
Пример |
|
КОЛИЧ |
Двадцать восемь |
|
СУЩ-ЧИСЛ |
статья 123 |
|
ОДНОР_ПРИЛ |
первой и единственной |
|
НАР_ПРИЛ |
очень красивый |
|
ОДНОР_НАР |
долго иль коротко |
|
ОДНОР_ИНФ |
стоять или лежать |
|
СРАВН-СТЕПЕНЬ |
гораздо сильнее |
|
НАРЕЧ-ГЛАГОЛ |
красиво жить |
|
ПРИЛ-СУЩ |
длинная унылая дорога |
|
НАР-ЧИСЛ-СУЩ |
много очень простых
ребят |
|
ЧИСЛ-СУЩ |
сорок восемь попугаев |
|
ПГ |
на холме |
|
ПРЯМ_ДОП |
рубить дрова |
|
ОДНОР_ИГ |
мама и папа |
|
ГЕНИТ_ИГ |
рука Москвы |
|
И Т.Д. |
|
Пример:
Я видел дом, который построил хороший человек
G1 = {ПРЯМ-ДОП,"видел дом
", "видел " }
G2 = {ПРИЛ-СУЩ," хороший
человек ", " человек " }
Результатом
работы этого процессора является объединенное дерево, в котором собраны как
результаты работы фрагментации, так и синтаксического анализа. В узлах этого дерева стоят либо слова, либо
жесткие группы (типа электронный адрес).
Пятый процессор – первично
семантический анализ, принципиальная организация которого и отдельные модули
собственно вынесены на защиту.
Сам термин семантический анализ,
несмотря на очевидную популярность, не является устоявшимся. Теоретические
лингвисты и вообще гуманитарии понимают этот термин гораздо глубже, чем
прикладные. Под семантикой обычно понимают экспликацию смысла слов и выражения
путем их толкования. Однако многие специалисты приходят к выводу о невозможности эффективной алгоритмической
реализации семантического анализа через толкования. Таким образом толкование
теряет свое прикладное значение. Что же
остается для прикладной семантики и что отличает ее от синтаксиса? Подход, который мы взяли за основу, называют
информационно-ролевым подходом. Это означает, что смысл текста выражается
графом, в узлах которого стоят леммы
или единицы, которые равны по объему словам, типа числительные, которые в
русском языке выражаются многословной конструкцией, или связка "быть", которая в русском языке иногда
опускается. Отношения этого графа
задаются перечнем и называются семантическими отношениями. Традиционный
школьный синтаксис, который строится на понятии согласования, управления и
примыкания, позволяет очертить круг синтаксических отношений. Все алгоритмы,
которые ищут эти отношения и их композиции, можно назвать синтаксисом.
Семантикой мы называем те алгоритмы, которые, используя смысл слов и выражений,
устанавливают отношения, которые не вычисляются напрямую из синтаксических отношений.
Конечно, нельзя преувеличивать значение семантического анализа для систем
автоматической обработки текста. Если
попытаться просчитать актуальность семантического анализа как довеска к
традиционному синтаксическому хотя бы на примере системы ДИАЛИНГ, то его помощь
составляет не более десяти-двадцати процентов.
Теперь мы кратко опишем
теоретическую базу, на основе которой
был разработан первично семантический процессор – т.е., семантическая система
доктора технических наук Н.Н. Леонтьевой.
В центре этой теории находится
Русский общесемантический словарь, или РОСС, который включает семантическое
описание по следующему шаблону:
-
Семантический класс лексемы (набор семантических
характеристик);
-
Грамматический класс лексемы;
-
Валентная структура
лексемы (в терминах семантических отношений);
-
Семантические и грамматические ограничения на выражение
каждого актанта из валентной структуры;
Ниже приведен пример словарной
статьи глагола"винить".
|
Пример 6. Словарная статья глагола "винить": |
^ |
ЗГЛ = винить 1
КАТ = 1 ЭТК.СИТ
ГХ = 1 ГЛ:ГГ
СХ = 1 ИНТЕЛ
2 КОММУНИК
ВАЛ = АГЕНТ , А1 , С
ОБ , А2 , С
СОДЕРЖ , А3 , С
ГХ1 = 1 подл : И
СХ1 = 1 ОДУШ
ГХ2 = 1 п_доп : В
СХ2 = 1 ОДУШ
2 АБСТР
ГХ3 = 1 к_доп : в+П
2 к_доп : за+В
АНГ = blame 1
ИЛЛ = Я сам себя винил во всех неудачах.
Винить за это некого.
Опишем кратко понятие
семантической характеристики и отношения.
Семантическое отношение - это некая универсальная связь,
усматриваемая носителем языка в тексте.
Формат записи семантического отношения следующий:
R(А,B), где R – название
семантического отношения, А – зависимый член отношения, B – управляющий член
отношения.
Для конкретных А,B и отношения R направление выбирается таким образом,
чтобы формула R(А,B) была эквивалентна утверждению, что "А является R для B".
Например, для фразы роман Толстого будет построена формула АВТОР(Толстой,
роман), а не наоборот, потому что верно утверждение "Толстой является АВТОРом
романа".
Соответственно, эта проверка и является базисной оценкой правильности
проведения одного отношения от узла А к узлу
B. Если все базисные проверки
пройдены, то и весь граф признается правильным, т.е. отражающим смысл входного текста.
|
Схема 7. Семантические отношения |
^ |
Семантическое отношение
R (A, B) <=> "А является R для B"
Перечень
отношений:
|
Название(R) |
Примеры |
|
АВТОР |
Роман Толстого |
|
АГЕНТ |
Мы сократили отставание |
|
АДР |
Я отдал стул отцу. |
|
ВРЕМЯ |
Это произошло вчера. |
|
ИДЕНТ |
Дом N 20 |
|
ИМЯ |
Дворник Степанов |
|
ИНСТР |
резать ножом |
|
ИСХ-Т |
яблоки из Молдавии |
|
КОЛИЧ |
два яблока |
|
КОН-Т |
уехать в Москву |
|
ЛОК |
жить в глуши |
|
ОБ |
уничтожить мост |
|
ОЦЕНКА |
хорошо относиться |
|
ПАЦИЕН |
арест преступника |
|
ПРИЗН |
красивый шар |
|
ПРИНАДЛ |
дом отца |
|
ПРИЧ |
деревья повалены ураганом |
|
РЕЗЛТ |
испечь пирог |
|
СОДЕРЖ |
рассказать о весне |
|
СПОСОБ |
идти босиком |
|
СРЕДСТВО |
красить белилами |
|
СУБ |
любовь отца |
|
ЦЕЛЬ |
забастовка в целях
повышения зарплаты |
|
ЧАСТЬ |
ножка стула |
Семантические характеристики (СХ) в словаре РОСС играют важнейшую роль.
В словаре РОСС семантических характеристик около 40. Из этих меток
строятся формулы (с логическими связками и, или). Каждому слову приписана
некоторая формула, составленная из СХ.
СХ используются для сборки
валентной структуры. Для каждого i-го актанта в поле СХi записывается формула,
которой он должен удовлетворять.
Хотя изначально СХ вводились как простые селективные ограничения,
отбраковывающие некоторые связи, проведенные синтаксическим анализом, теперь за
каждой из них закреплено определенное значение. Вообще говоря, считается, что если СХ(А) = СХ (B) <=> "А и В имеют общее семантическое
свойство".
|
Схема 8.
Семантические характеристики |
^ |
Семантическая характеристика
СХ (A) = СХ(B) <=> "А имеет смысловое сходство с B"
Пример
СХ (говорить) = СХ(орать) =
КОММУНИК
СХ (повар) = СХ(генерал) = ДОЛЖ
Перечень
семантических характеристик:
|
Название |
Примеры |
| АБСТР |
модель, план, |
|
АРТ |
хлеб,памятник |
|
ВЕЩВО |
бензин,ядохимикат |
|
ВМЕСТЛ |
мешок, амбар |
|
ВОСПР |
слушать, видеть |
|
ДВИЖ |
идти, ронять |
|
ДОЛЖ |
повар,партработник |
|
Д-УСТР |
карбюратор,валик |
|
ИЗМ |
наращивать,реформировать, |
|
ИНТЕЛ |
надеяться,изучать, |
|
ИНФ |
знание,команда, |
|
КОММУНИК |
выражать,выступать |
|
НОСИНФ |
книга,газета, |
|
Н-ТРЕБ |
закон,инструкция |
|
ОДЕЯТ |
физика,балет |
|
ОДУШ |
папа,президент |
|
ОРГ |
колхоз,школа |
|
ПРЕДМ |
марка, бинокль |
|
ПРОТЯЖ |
дорога,граница |
|
СОБИР |
библиотека,молодежь |
|
УСТР |
компьютер,лифт |
|
ЭМОЦ |
мизерный,могучий |
|
ЯВЛЕН |
смерч,терроризм |
| И Т.Д |
|
Сложные формулы:
СХ(библиотека) = СОБИР, НОСИНФ
СХ(молодежь) = СОБИР, ОДУШ.
СХ(бесчувственно) = ОТСУТ, ЭМОЦ
Мы описали основные досемантические компоненты системы ДИАЛИНГ и
аппарат семантического анализа, который был взят нами за основу. Теперь перейдем к описанию
первично семантического процессора.
На вход семантического процессора
подается синтаксическое дерево, а в большинстве случаев множество несвязных
синтаксических деревьев, т.е. лес. Задача состоит в том, чтобы по возможности
разрешить морфологическую, лексическую и древесную неоднозначность.
|
Схема 9. Вход и выход первично семантического анализа |
^ |
|
Вход: синтаксическое дерево |
|
Выход: семантический граф |
| R(a, b) |
=> |
R(A,
B) |
| генит,иг(дом, отца) |
=> |
ПРИНАДЛ(дом, отца) |
| генит_иг(чашка, чая) |
=> |
КОЛИЧ(чашка, чай) |
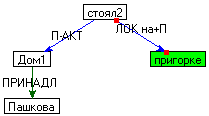
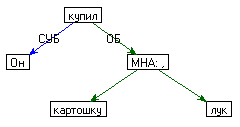
Примеры семантической структуры для
предложения
| Дом Пашкова стоял на пригорке. |
|
Он купил картошку, лук. |
 |
|
 |
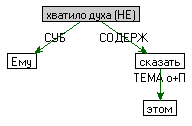
| Ему не хватило духа сказать об этом. |
|
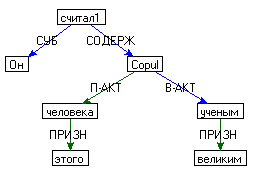
Он считал этого человека великим ученым. |
 |
|
 |
Под морфологической
неоднозначностью мы понимаем омонимию в
морфологическом словаре. Например, словоформа "стали" – как "стать" и как
"сталь". Под лексической неоднозначностью – то когда для одной лемме в
семантическом словаре соответствует много словарных статей, например "ему не
доставало ласки" <=> "ребенок не достает до полки". Древесная
неоднозначность иллюстрируется на фразе "Мать любит дочь", где неясно кто кого
любит. Типы неоднозначности задают
устройство первично семантического
модуля.
|
Схема 10.
Неоднозначность, с которой сталкивается анализатор |
^ |
Морфологические варианты
Клинок сделан из стали.
Мы
стали лучше.
Лексические варианты:
Ему не доставало ласки
Ребенок не достает до полки
Древесные
варианты
Мать
любит дочь
Синтаксический анализ снимает почти
всю морфологическую омонимию. Однако часть ее доходит до семантики. Если
синтаксический анализ рассматривает морфологические варианты только внутри
одного фрагмента, то семантика разбирает
морфологические варианты всего предложения.
Работа внутри одного
морфологического варианта состоит из
следующих основных процедур:
- построение групп времени;
-
поиск закрытых словосочетаний;
-
интерпретация узлов, полученных из синтаксиса в семантических
словарях.
Поскольку первые две
процедуры касаются словосочетаний,
самое время объяснить, как устроено
алгоритмическое деление словосочетаний в системе ДИАЛИНГ. Классификация
эта построена на двух дихотомиях:
условные и безусловные и открытые и закрытые.
Словосочетание объявляется
условным, если выполнение всех синтаксических и лексических требований к
словосочетанию еще не является достаточным условием их существования в тексте,
в противном случае оно объявляется безусловными. Безусловные словосочетания
обладают повышенной идиоматичностью. Условные словосочетания требуют
семантических свидетельств в пользу их существования, поэтому в семантическом
анализе должны рассматриваться обе альтернативы.
Открытое словосочетание отличается
от закрытого тем, что каждый элемент открытого словосочетания получает
отдельную словарную интерпретацию, а закрытое словосочетание может получить только
интерпретацию в целом. Поскольку элементы открытого словосочетания получают
собственную словарную интерпретацию, они могут присоединять по валентностям
другие узлы.
Вышесказанное может быть сведено в
следующую таблицу:
|
Таблица 11. Типы
словосочетаний |
^ |
|
Словосочетания = |
безусловные открытые
( термины) |
Безусловные закрытые
(обороты,Тайм-группы) |
Условные открытые
(???) |
Условные закрытые
(устойчивые словосочетания) |
Таблица
эта задает алгоритмическое деление, а теперь рассмотрим деление словосочетаний
по словарям.
Термины - это единицы тезаурусов. По структуре тезаурусы унаследовали
многое из системы ПОЛИТЕКСТ, а те в свою очередь от традиционных тезаурусов,
т.е. отношение ЧАСТЬ-ЦЕЛОЕ и ВЫШЕ-НИЖЕ и синонимия. Главное отличие тезаурусов
ДИАЛИНГ от тезаурусов ПОЛИТЕКСТа заключается в следующем:
-
В тезаурусах хранится исключительно именная предметная
лексика.
-
Каждый текстовый вход может
быть снабжен словарной статьей в стиле РОСС.
-
Концепты тезауруса используются в качестве селективных ограничений
(как СХ) в словаре РОСС.
Таким образом, в системе ДИАЛИНГ
словарь РОСС и тезаурусы находятся в эксплицитных дополнительных отношениях.
Устойчивые обороты включают в
себя сложные предлоги и сложные
союзы и некоторые обстоятельственные группы. Формально обороты были
отнесены к классу безусловных закрытых словосочетаний, но надо сказать, что в
последнее время пришлось часть оборотов объявить условными. Вот, например,
цепочка"то есть" (которая чаще всего является союзом) во фразе"если ты уйдешь, то есть шансы, что тебя
выгонят" таковым не является.
Группы времени – это открытые
словосочетания, заполняющие валентность времени у слов ситуаций, например"2
октября 1999 года". Эти словосочетания собираются по чисто синтаксическим
критериям, но внешняя их роль – чисто смысловая. Автору данной диссертации
принадлежит идея этого словаря, частично структура словарной статьи и
программная реализация алгоритма поиска групп времени. Особенности обработки
групп времени можно
проиллюстрировать двумя примерами:
- словосочетание"на 27
августа" формально считается предложной
группой, а предложные группы в системе
ДИАЛИНГ собираются на синтаксисе. Но чтобы "на 27 августа" собралось как предложная группа, нужно чтобы "27 августа" собралось как именная группы, а
это чисто временная конструкция.
- Словосочетание "пять лет" во фразе"Он работал пять лет" заполняет валентность времени, а во фразе"Пять лет прошло" роль субъекта. В
частности, на разрешение этой
неоднозначности направлена часть описательных средств словаря групп времени .
Словарь устойчивых словосочетаний содержит перечень
закрытых условных словосочетаний. Эти словосочетания типа"бить баклуши","пустить красного петуха" обладают бОльшей идиоматичностью, чем все
остальные словосочетания проекта
Диалинг. Поэтому почти все они могут считаться безусловными, хотя есть и
такие, например
-
Он взял верх в поединке
Возьмем верх картины и
отрежем его.
- Мы приняли
ваше мнение в расчет.
Мы приняли нового солдата в боевой расчет.
Из-за этих примеров и им подобных мы
считаем этот класс словосочетания условным.
Видно, что
эти две дихотомии – это чистые
эвристики, необходимые для правильного положения процедуры поиска
словосочетания в анализе. Как только мы понимаем, что словосочетание условно,
мы должны помещать его на этап семантики, в противном случае она может остаться
на синтаксисе.
Правило построение словарной
интерпретации для узлов. В проекте ДИАЛИНГ используются следующие русские
словари: РОСС, ТаймРОСС, Обороты, Словосочетания, Локативный, финансовый,
компьютерный и общий тезаурусы. Каждый из них содержит словарные статьи,
которые могут быть интерпретациями
узлов. Словарной интерпретацией считается пара <Имя словаря, номер
статьи>. Для узлов, которые не найдены в словарях, есть словарные
статьи-заглушки, которые интерпретируют узел по его грамматическим
характеристикам. Например, для переходного глагола создана своя
статья-заглушка. Словарная интерпретация может быть осложнена грамматической
формой узла. Например, совершенный вид глагола интерпретируется по статье
несовершенного глагола, если для него нет отдельной статьи.
Таким образом, теперь каждому узлу
приписано множество статей. Лексический вариант – это один из вариантов
приписывания словарных статей узлам. Здесь работают следующие процедуры:
-
Получение перечня валентностей для каждого узла;
-
Построение всех возможных гипотетических связей по ГХi;
-
Обработка однородных конструкций;
-
Процедура получения одного древесного варианта.
Первая процедура – получает для
каждого узла перечень валентностей из статей. Здесь необходимо учитывать, что в
валентностях иногда используется оператор несовместности. Таким образом, узлу
бывает приписан не один набор, а целое множество наборов. Кроме того,
существуют добавочные валентности,
которые возникают у целых классов слов. Например,
СХ = ВМЕСТЛ
ГХ1 = 1 к_доп : с+Т
ИЛЛ = мешок с зерном
Валентности в системе Диалинг бывают обязательные, обычные и
факультативные.
Вторая процедура строит все возможные гипотетические связи,
основываясь на следующих параметрах:
-
Синтаксическая интерпретация узлов с одной стороны;
-
ГХi актанта, прописанные в статье, с другой стороны.
Процедура построения графа гипотетических связей почти всегда строит
граф, отношений в котором больше, чем нужно.
Например, если у некоторого узла есть валентность на именную группу в
родительном падеже, то проводятся все связи от этого узла к именным группам в
родительном падеже.
|
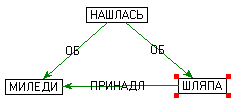
Пример 12. Граф гипотетических связей |
^ |
| Шляпа миледи нашлась. |
 |
Идеальным соотношением между
числом гипотетических связей и числом узлов была бы один. На обработанных нами примерах это соотношение колеблется от 1 до 2.
Соотношение между числом гипотетических связей и числом узлов может
использоваться в качестве оценки сложности фрагмента F (обозначение Compl(F)).
В текущей реализации фрагмент F считается сложным, если Compl(F) > 1.5, в
таком случае включаются некоторые программные упрощения.
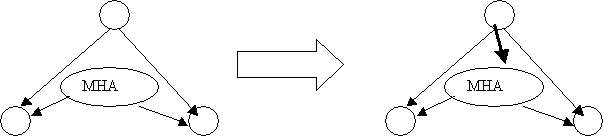
Третья процедура открывает новую тему семантического анализа –
множественные актанты, или МНА. Множественный актант - это такой узел, который объединяет все узлы,
заполняющие одну валентность. Множественный актант обрабатывается следующими процедурами:
- процедура
построения сравнительного оборота,
например с союзом чем, Он был больше учителем,
чем сторожем;
- процедура
построения предложного однородного
ряда, например: В лесу и на огороде;
- процедура
построения отношений, выходящих из оператора однородности для простых
однородных рядов типа Иван, Петр
и Мария;
Основной механизм работы с множественными актантами следующий. Сначала
по стандартным законам проводятся связи к членам однородного ряда от
потенциального хозяина и от оператора однородности. Затем, запускается процедура, которая проходит по всем операторам однородности, если Х подчиняется
одновременно оператору однородности и другому узлу Y, тогда проводится стрелка
от Y к оператору однородности.
|
Схема 13. Основное правило однородности |
^ |
 |
| Последняя процедура обработки лексического варианта – построение
множества древесных вариантов. |
Это процедура занимает больше
всего времени работы программы. В системе ФРАП такой процедуры не было.
Реализация этой процедуры принадлежит автору данной работы. Мне известно две реально работающих системы,
в которых эта проблема была решена: 1. Система ЭТАП; 2. Система
Микрокосмос. Самым полным решением этой проблемы является простой
перебор всех возможных остовных деревьев в графе гипотетических связей. Система ЭТАП решает проблему неоднозначности для каждого конкретного узла (я
сужу по описанию системы ЭТАП2). Таким образом, выбор одного варианта не зависит от выбора другого варианта, если
только они не имеют непосредственной связи. Кроме этого, при таком подходе
неясно, в какой последовательности надо разрешать неоднозначность на узлах и
приходится создавать специальные алгоритмы, которые пытаются вычислить
предварительно эту последовательность.
В системе ДИАЛИНГ сначала мы реализовали процедуру полного перебора.
Однако, потом выяснилось, что на клаузах с сложностью больше, чем 1.5 система
работает очень долго. Тогда мы воспользовались
методом проекта МикроКосмос,
который кратко можно описать следующим образом.
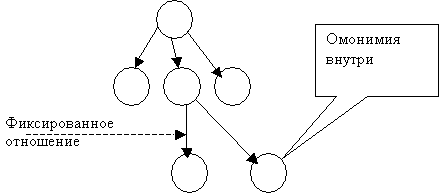
Граф гипотетических связей разбивается на компоненты, для
которых верно, что N-N1 минимально и положительно, где N – число узлов в подграфе, а N1 –
количество узлов, имеющих отношения с узлами,
не входящих в подграф. Все вершины, которые не имеют внешних связей
могут быть вычислены внутри этой компоненты. Дальше строятся деревья внутри этих компонент. Дальше опять ищутся
компоненты еще бОльшие и т.д.
|
Схема 14. Процедура построения
древесных вариантов в системе Микрокосмос (1996) |
^ |
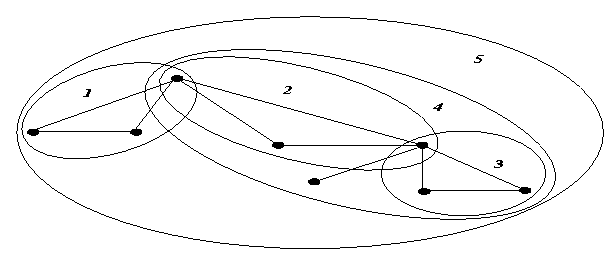 |
| Сначала решаем
древесную неднозначность в подграфе 1, потом 2 и т.д. |
Но метод
системы Микрокосмос – это метод
снятия лексической
неоднозначности. На данном же этапе в системе ДИАЛИНГ лексический вариант уже определен и решается задача получения древесного варианта. Поэтому, переняв основную идею, необходимо
было этот метод адаптировать. Будем рассматривать только те компоненты
связностей, которые имеют не более одной связи с другой компонентой. Делается
это с помощью фиксированных отношений.
Отношение является фиксированным, если нет другого отношения, идущего в этот
узел. Если предположить, что циклов в гипотетическом графе нет, а
ориентированных циклов там действительно почти не бывает. Тогда фиксированные
отношения, гарантированно останутся в
заключительных вариантах дерева, поскольку основной критерий – это связность.
Таким образом, фиксированные отношения превращают граф гипотетических связей в
дерево (в лучшем случае), где в узлах стоят компоненты связностей, внутри
которых надо построить деревья. Соответственно, процедура полного перебора
сначала строит лучшие деревья в этих компонентах. А потом лучшие деревья для
всей клаузы сразу, которое состоит из лучших вариантов компонент и
фиксированных отношений.
|
Схема 15. Процедура построения древесных вариантов в системе Диалинг |
^ |
Понятно, что этот метод слабее, чем метод полного перебора,
поскольку не учитываются зависимость вариантов между компонентами связностей.
Однако, было проведено тестирование этой процедуры. Ни одного противоречия к
этой технике найдено не было, в то
время как количество вариантов по сравнению с полным перебором уменьшилось в
несколько раз.
Оценка деревьев это главная процедура семантического анализа.
По нашему глубокому убеждению,
в естественном языке не существует полностью неправильных фраз или предложений,
а есть некоторая шкала правильности. В этом духе сделана процедура оценки
деревьев, и именно: существует набор процедур, каждая из которых выдает
числовую оценку получившегося дерева.
Сумма оценок и есть вес графа.
Лучший по весу – лучший граф. Каждой процедуре приписан некоторый
коэффициент важности, таким образом
можно объявить одну ошибку грубее
другой. Поскольку некоторые процедуры оценки зависят от количества узлов в
графе, то приходится нормировать их, т.е. делить на число узлов.
Конечно, многие из этих
весов-процедур общеизвестны, хотя некоторые все же уникальны. Но главная особенность всей системы
заключается именно в том, что оценивание графов происходит на самом последнем
этапе, а оценка происходит интуитивно понятными и лингвистически обоснованными средствами. Таким образом,
происходит скрещивание процедур
близких к полному перебору (хотя, конечно, ими не являющихся) и элементарной
лингвистической интуиции, что все вместе является гарантом хорошего результата.
|
Схема 16. Оценка древесного варианта |
^ |
Основные критерии
- одна валентность не может заполняться дважды;
- число компонент связностей должно быть минимально;
Дополнительные критерии
- (структурные)
- Проективность;
-
Длина отношений;
-
Порядок актантов в тексте;
-
Нарушение оператора МНА;
-
Незаполненные обязательные валентности;
-
Заполненные факультативные валентности;
-
Согласование по СХ;
- (словарные)
- Общее число валентностей,
которые заполнены одним из значений
стандартной лексической функции (поле ЛХ);
- Число узлов, построенных на лексических функциях;
- Число закрытых словосочетаний;
- Нарушения Copul;
- (массив)
- Число
слов, имеющих одинаковую предметную область;
- Число слов с пометой ПО=разг;
- Число слов, входящих в ядро языка.
- (грамматические)
- Равна или нет вершина
построенного графа сказуемому в синтаксическом анализе;
- Число узлов, нарушающих
грамматические ограничения, записанных
в поле ОГРН;
- Удовлетворяет ли корень дерева морфологическим критериям;
- Проверка согласования подлежащего и сказуемого;
После того
как было построено дерево для каждой клаузы запускается процедура построения
межклаузных связей. Здесь отрабатывает набор
правил, каждому из которых на вход приходит пара клауз, а оно (т.е. это
правило) проверяет можно ли связать эти
две клаузы. Если не получилось собрать
дерево, то пробуются разные
наборы пар клауз. Эти правила во основном ищут атктанты для незаполненных
валентностей в других клаузах.
После отработки этого правила
граф для целого предложения уже собран, и в принципе, задача первично
семантического анализа выполнена.
- Леонтьева Н.Н. Строение семантического компонента
в информационной модели автоматического понимания текста. Автореф. и дисс.
д.т.н. М., 1990.
- Леонтьева Н.Н.
Русский общесемантический словарь (РОСС): структура, наполнение. // НТИ.
Сер. 2. - 1997. - N 12. - С.5-20.
- Mahesh K. (1996) Ontology development for
MT: Ideology and Methology. NMSU CRL Technical Report. MCCS-96-292.
главная о нас продукты скачать демо технологии ^ |